

Na przestrzeni ostatnich lat maszyny stały się w wielu rzeczach niemal tak dobre (a czasem i lepsze) jak ludzie. Często w przypadku diagnozy czy rozpoznawania obrazu Sztuczna Inteligencja jest szybsza niż człowiek.
Deep Learning
Deep learning, czyli – dosłownie – głębokie uczenie to proces, który ma na celu tworzenie sztucznych sieci neuronowych. Działa to na zasadzie swoistego treningu. Sztuczna Inteligencja otrzymuje bazę danych, na podstawie której uczy się przewidywać wydarzenia lub też rozpoznawać szczegóły. Przykładem jest chociażby system rozpoznawania mowy.
Dzięki odpowiedniej bazie danych, gdzie lektorzy czytają specjalnie wyselekcjonowane zdania Sztuczna Inteligencja jest w stanie z czasem nauczyć się rozpoznawać ludzką mowę.
Problem pandemii
Deep learning może być bardzo pomocny przy rozumieniu pandemii oraz przy planowaniu działań z nią związanych. Epidemiologowie opracowali odpowiedni model rozprzestrzeniania się zarazy. Model odnosi się do jednostek podatnych (nie tych, które wyzdrowiały). Głównymi wariantami modelu są: wskaźnik zarazy nazywany R0 (jak szybko choroba się rozprzestrzenia) oraz czas, którym jednostki mogą zarazić kolejne – D.
Podczas pandemii epidemiologowie potrzebują wiedzieć jak najwcześniej jak szybko choroba będzie się rozprzestrzeniać. Pozwala to chociażby oszacować kiedy – i czy w ogóle – szpitale zostaną przepełnione.
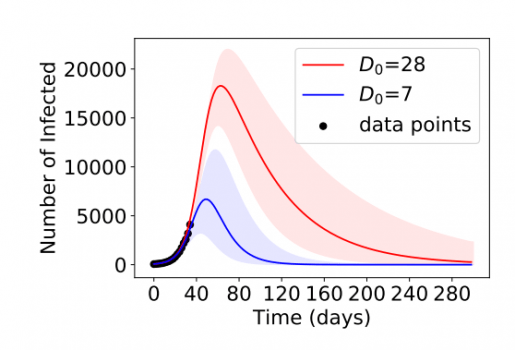
Dane niedostatecznie określone
Teraz, gdy bardziej niż kiedykolwiek, polegamy na analizie ze strony Sztucznej Inteligencji naukowcy muszą lepiej zrozumieć jej ograniczenia. Zespół składający się głównie z naukowców pracujących dla Google zidentyfikował potencjalną wadę w systemie głębokiego uczenia. Mowa tu o danych, które nie są wystarczająco określone. Zespół wykazuje wpływ wady w wielu aspektach, gdzie wykorzystuje się deep learning. Mowa tu o maszynach i programach zaprojektowanych do rozpoznawania obrazów czy nawet Sztucznej Inteligencji wspomagającej dziedziny takie jak genomika.
Wracając do pandemii. Naukowcy, wcześnie podczas rozprzestrzeniania się zarazy zdobywają informacje na temat wartości wskaźników R0 i D. Oczywiście są to estymacje. Następnie prezentują dane Sztucznej Inteligencji, która szacuje rozwój choroby. Zespół naukowców, który bada limity głębokiego uczenia uważa, że dane te są niekompletne. A oznacza to, że uderzają w słaby punkt deep learningu – dane niedostatecznie określone. Podczas ich badań otrzymali tak różne rezultaty, nieznacznie tylko zmieniając parametry, iż uważają że nie jest to odpowiedni system do estymowania rozwoju pandemii.
Co więcej zespół poszedł o krok dalej. Nieznacznie zmodyfikował wskaźniki w innych dziedzinach. Sprawdzono rozpoznawanie obrazów medycznych, diagnozę kliniczną czy przetwarzanie języka naturalnego. We wszystkich przypadkach otrzymali oni wyniki bardzo od siebie oddalone. Za bardzo.
Obecnie opracowano odpowiednie testy, które są w stanie sprawdzić czy w danym przypadku występuje wspomniana w tytule luka. Niestety, wymaga to odpowiednio dobrze przebadanych informacji, z którymi porównuje się wyniki. W przypadku nowych dziedzin należy pamiętać, że Sztuczna Inteligencja może się mylić. I to bardzo.
Źródło: discovermagazine.com, Underspecification Presents Challenges for Credibility in Modern Machine Learning






